GEO и SEO в 2026: как попасть в ответы ChatGPT и Perplexity
Мы изучили около полутора часов свежего контента по теме продвижения сайтов в условиях, когда традиционный поиск теряет аудиторию в пользу AI-систем. Материалы охватывают три угла: классическое SEO для нового сайта, автоматизированную генерацию контента под AI-поиск и технический чеклист для попадания в базы ChatGPT. Статья будет полезна тем, кто уже работает с SEO и хочет понять, куда двигаться дальше, — не в теории, а с конкретными шагами.
Главный вывод, который прослеживается во всех материалах: AI-поиск — это не отдалённое будущее, это уже конкурирующий канал трафика с аномально высокой конверсией, и окно для раннего входа закрывается прямо сейчас.
Что происходит с трафиком и почему это важно именно сейчас
Начнём с цифр, потому что они неудобные.
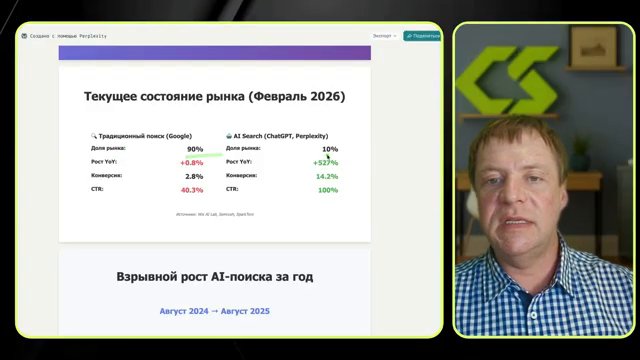
60% поисковых запросов в Google уже не генерируют клик на сайт. 27% поисков заканчиваются вообще без какого-либо перехода. Это не прогноз — это данные за 2024–2025 год. Пользователь задаёт вопрос, получает ответ прямо на странице выдачи (через Google AI Overview) или уходит в ChatGPT — и сайты из топа остаются ни с чем.
При этом AI-поиск растёт на +527% относительно роста традиционного поиска (+0,8%). За 2024–2025 год аудитория AI-поисковиков удвоилась (+150%). 29% интернет-пользователей уже используют AI-поиск ежедневно.
А вот тут самое интересное. Конверсия с AI-трафика — 14,2%. С традиционного поиска — 2,8%. Разница в пять раз. При этом CTR (переход на сайт) с AI-поиска — 100%: если ChatGPT или Perplexity называет ваш сайт, пользователь практически всегда на него переходит. В классической выдаче этот показатель — около 40%.
Один из разборов, которые мы изучили, содержал конкретный кейс: 5–6 визитов с ChatGPT в месяц давали 3–4 конверсии. Это не опечатка. Конверсия в районе 60–70% с одного источника — такого в SEO не бывало никогда.
К 2026 году традиционный поиск, по оценкам аналитиков, потеряет ещё 20% трафика в пользу AI-систем. Рынок AI-поиска сейчас — 10% от общего объёма. Кто зайдёт первым, займёт позиции надолго. Ровно как это было с SEO в 2005-м.
Как ChatGPT узнаёт о вашем сайте: механика без мифов
Здесь важно понять реальный механизм, а не гадать.
ChatGPT не сканирует интернет самостоятельно. Он обучается на базе Common Crawl — открытого датасета, который сам сканирует сайты по всему интернету. Попасть в Common Crawl можно только косвенно: создавая публичный, популярный, проиндексированный контент.
Три слова — и каждое важно: - Публичный — без авторизации, без капчи, без JavaScript-блокировок - Популярный — с реальной активностью: ссылки, упоминания, лайки, комментарии - Проиндексированный — доступный для поисковых роботов через открытый robots.txt
Обновляется база с задержкой. Вот реальная хронология версий GPT: - GPT-3.5 — данные до середины 2021 года - GPT-4 (март 2023) — частично данные за 2022 год - GPT-4 Turbo — данные до октября 2023 года - Актуальная модель (середина 2025) — данные до середины 2024 года
Вывод: если вы не создаёте контент сейчас, в следующую обучающую базу попадут данные конкурентов, а не ваши. Ждать — значит терять полгода-год.
Google AI Overview работает иначе. Gemini обновляется в реальном времени — предположительно, синхронно с каждым Core Update, поскольку Google имеет прямой доступ ко всей проиндексированной базе. Это означает, что классическое SEO здесь работает напрямую: если вы в топе Google, шансы попасть в AI Overview существенно выше.
ChatGPT с функцией поиска использует Bing. Не Google. Это критично: если вы не ранжируетесь в Bing, вас нет в результатах поиска ChatGPT, когда пользователь явно просит его «найти в интернете».
Один важный момент насчёт манипуляций: нельзя «обучить» ChatGPT через запросы. Если написать модели, что она ошибается, она исправится только в рамках текущей сессии. Система защищена от таких попыток. Единственный путь — попасть в датасет через контент.
GEO: что это такое и чем отличается от SEO

GEO (Generative Engine Optimization) или LLMO (Large Language Model Optimization) — оптимизация контента для попадания в ответы AI-систем. Не в поисковую выдачу, а именно в генерируемые ответы.
Суть простая: когда пользователь спрашивает Perplexity «где купить демисезонную куртку в Москве», система генерирует ответ и называет конкретные магазины. Вот эти магазины — и есть результат GEO. Их сайты попали в рекомендации AI. Остальные — нет.
Разница с классическим SEO принципиальная:
| Параметр | SEO | GEO |
|---|---|---|
| Цель | Позиция в выдаче | Упоминание в ответе AI |
| Метрики | Позиции, CTR, трафик | Пока нет стандартных |
| Скорость результата | 3–12 месяцев | 2–6 месяцев (первые данные) |
| Конверсия трафика | ~2,8% | ~14,2% |
| Инструменты анализа | Semrush, Ahrefs, GSC | Perplexity, ручной мониторинг |
Один из разобранных нами материалов прямо предупреждает: у GEO пока нет измеримых метрик в привычном понимании. Нельзя поставить в дашборд «позиция в ChatGPT по запросу X» и отслеживать её ежедневно. Это неудобно, но честно. Метрики появятся — рынок молодой.
Технический фундамент: что должно быть на сайте
Разберём по пунктам. Это не абстракция — это конкретный чеклист, который мы собрали из нескольких разборов.
Базовая техническая оптимизация
- robots.txt — открыт для всех основных страниц. Закрывать только то, что точно не нужно в индексе
- Уникальный тайтл и мета-описание — на каждой индексируемой странице, без дублей
- Иерархия заголовков — один H1, затем H2 и H3 в логичном порядке
- ЧПУ (человекопонятные URL) — без цифровых ID и случайных символов
- Контент без JS-блокировок — если текст появляется только после скрипта, Common Crawl его не видит. Это критическая ошибка
RSS-фиды — недооценённый инструмент
Большинство сайтов игнорируют RSS. А зря: именно через RSS-агрегаторы Common Crawl забирает данные.

Что нужно: - RSS или Atom-фид для всех страниц сайта, включая страницы категорий (если там есть текстовый контент) - Фид должен содержать: заголовок, дату, автора, ссылку и полный текст материала — не анонс - Доступен без авторизации и капчи - Зарегистрировать сайт в Feedle (агрегатор RSS-фидов) - Добавить сайт в Google Publishers как блог — это отдельная опция, доступная не только новостным изданиям
Микроразметка: четыре обязательных типа
Отсутствие микроразметки — серьёзная проблема для попадания в AI-ответы. Нужно добавить:

- Article — для страниц блога и инструкций
- WebPage — для всех страниц сайта
- FAQPage — для блоков вопросов и ответов
- BreadcrumbList — на всех страницах, кроме главной
Дополнительно: Facebook OpenGraph — разметка для корректного отображения ссылок в мессенджерах. ChatGPT использует её при распознавании контента страницы.
Лицензия и разрешения для AI

Это делают единицы, а работает. Нужно:
- Разместить на сайте лицензию CC BY 4.0 или CC BY-SA 4.0 — в файле LICENSE.md или в HTML-документе
- В политике использования сайта и/или в robots.txt явно указать, что контент доступен для AI-исследований и обучения
Common Crawl и AI-системы учитывают это при формировании датасетов.
Контент для GEO: структура, которую видит AI
Обычные SEO-статьи не попадают в рекомендации AI-поисковиков. Нужна другая архитектура.
Что должно быть в статье для GEO: - Введение с чётким ответом на вопрос (AI любит прямые ответы в начале) - Структурированные списки и таблицы - Ссылки на авторитетные источники (не просто утверждения — подтверждённые данные) - Блок FAQ — обязательно на основе реальных поисковых подсказок, не выдуманных вопросов - Внутренняя перелинковка с уже опубликованными материалами - Офферы — мягкий (в середине статьи) и жёсткий (в конце)
Важное предупреждение насчёт структуры: если каждая статья на сайте имеет одинаковое расположение блоков, поисковые системы начинают воспринимать их как шаблонный контент. Расположение таблиц, FAQ и офферов должно динамически меняться от статьи к статье.
Что писать: подборки с указанием года («Лучшие сервисы 2026 года»), сравнения, практические гайды с конкретными цифрами. Такой контент охотнее попадает в датасеты. Темы, которые уже хорошо освещены в сети, — низкий приоритет. AI-системы предпочитают уникальный контент, которого мало.
Видео — отдельная история. ChatGPT не видит, что происходит внутри видео. Единственный способ донести видеоконтент до AI — опубликовать расшифровку текстом на сайте или на внешних платформах (Medium, Dev.to) со ссылкой на оригинал.
Дистрибуция: где размещаться, чтобы попасть в датасет
Технический сайт — необходимое условие, но недостаточное. Common Crawl отдаёт приоритет популярному контенту. Нужны внешние сигналы.
Платформы для дублирования контента: - Medium и Dev.to — регистрироваться как автор, дублировать статьи со ссылкой на оригинал - Reddit — вести собственные ветки (subreddits) или публиковаться в тематических, добавлять ссылки на материалы. Критически важна реальная активность: лайки, комментарии, репосты. Накрутка не работает — Common Crawl отфильтровывает неорганическую активность - Stack Overflow — упоминание домена в контексте вопросов о своём проекте помогает попасть в базу
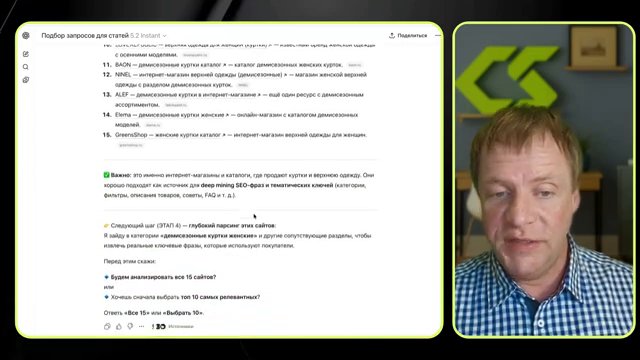
Как искать конкурентов в AI-поиске: не через Google, а через Perplexity. Запрос вида «демисезонные женские куртки, найдите 10 сайтов, верните только ссылки» — и вы видите, кого AI уже рекомендует. Именно этих конкурентов и нужно анализировать. Маркетплейсы и агрегаторы из списка исключаем — они не показательны для анализа стратегии.
Автоматизация: реально ли масштабировать GEO без ручного труда
Один из разобранных нами материалов полностью посвящён автоматизации производства GEO-контента. Система построена на n8n (платформа автоматизации) с управлением через Google Таблицы и публикацией в WordPress.
Что автоматизируется в такой связке: - Сбор LSI-ключей и длинных хвостов из поисковиков (Яндекс для России, Google для других рынков) - Исследование фактов по теме через Perplexity — статья не содержит выдуманных данных - Формирование архитектуры статьи агентом на базе Claude — структура динамически меняется - Генерация изображений (Midjourney, Flux Pro, Stable Diffusion) с сохранением единого визуального стиля - Вставка офферов в нужные места - Формирование FAQ из реальных поисковых подсказок - Перелинковка с уже опубликованными материалами - Публикация в WordPress с метаданными, тегами, рубриками и профилем автора
Темп публикаций важен. Начинать нужно медленно: 1 статья в 2 дня. Резкий старт с 3–5 статьями в день может навредить — поисковые системы воспринимают это как спам. Через 2 месяца можно выйти на 3–4 статьи в день. Первые результаты в виде трафика появляются примерно через 2 месяца после старта.
Стоимость самостоятельной разработки аналогичной системы на рынке — от 300 000 рублей. Часть подрядчиков вообще не понимает, как это реализовать. Это косвенно подтверждает, что рынок ещё не насыщен.
Что мы заметили: где материалы сходятся, а где расходятся
Сходятся все три источника: - AI-трафик конвертируется значительно лучше, чем органический поиск - Технический фундамент (индексируемость, структура контента, микроразметка) — обязательное условие для любого подхода - Начинать нужно сейчас: задержка на полгода означает пропущенный цикл обновления обучающих данных
Расходятся в акцентах:
Подход А делает ставку на автоматизацию и масштаб. Логика: производить много качественного структурированного контента быстро — и занимать темы раньше конкурентов. Инструмент — n8n + AI-агенты. Риск: при неправильной настройке темп публикаций может навредить.
Подход Б акцентирует техническую оптимизацию и дистрибуцию. Логика: сначала сделать так, чтобы сайт был технически «читаем» для Common Crawl, потом наращивать внешние сигналы через Reddit, Medium, RSS-агрегаторы. Это медленнее, но надёжнее для долгосрочного присутствия в датасетах.
Более консервативный взгляд на GEO напоминает: измеримых метрик пока нет, и это нужно честно признавать клиентам. Нельзя гарантировать «позицию в ChatGPT» так же, как позицию в Google. Это важно учитывать при продаже услуги.
На наш взгляд, оба подхода — не конкуренты, а дополнения. Технический фундамент + дистрибуция + автоматизация контента — это полный стек. Делать только одно из трёх — значит оставлять деньги на столе.
Практический чеклист: что сделать прямо сейчас
Разбиваем на блоки по приоритету.
Блок 1 — Технический аудит (1–2 дня) - [ ] Проверить robots.txt: открыты ли нужные страницы - [ ] Убедиться, что у каждой страницы уникальный тайтл и мета-описание - [ ] Проверить структуру заголовков: один H1, логичная иерархия H2/H3 - [ ] Убедиться, что контент не скрыт за JavaScript - [ ] Проверить URL-адреса: читаемые, без цифровых ID
Блок 2 — Микроразметка (2–3 дня) - [ ] Добавить Article на страницы блога - [ ] Добавить WebPage на все страницы - [ ] Добавить FAQPage к блокам вопросов и ответов - [ ] Добавить BreadcrumbList на все страницы, кроме главной - [ ] Проверить OpenGraph: отправить ссылку в Telegram и посмотреть превью
Блок 3 — RSS и агрегаторы (1 день) - [ ] Создать RSS-фид с полным текстом материалов - [ ] Зарегистрировать сайт в Feedle - [ ] Добавить сайт в Google Publishers как блог
Блок 4 — Лицензия и разрешения (2 часа) - [ ] Разместить лицензию CC BY 4.0 на сайте - [ ] Добавить разрешение для AI-агентов в robots.txt
Блок 5 — Дистрибуция (постоянная работа) - [ ] Зарегистрироваться на Medium и Dev.to как автор - [ ] Дублировать лучшие материалы со ссылкой на оригинал - [ ] Найти конкурентов через Perplexity (не Google) - [ ] Начать активность на Reddit в тематических ветках - [ ] Добавить расшифровки видео на сайт и внешние платформы
Блок 6 — Контент (постоянная работа) - [ ] Составить кластеры тем через Perplexity-анализ конкурентов - [ ] Начать публикации: 1 статья в 2 дня - [ ] Каждая статья: введение с ответом, списки, таблицы, FAQ из реальных подсказок, ссылки на источники - [ ] Через 2 месяца оценить результат и постепенно увеличивать темп
Рынок AI-поиска сейчас — это ранний Google. Кто занял позиции в 2005-м, собирал трафик годами. Кто пришёл в 2010-м — уже боролся с конкуренцией. Разница между «сделать сейчас» и «подождать ещё полгода» — это полный цикл обновления обучающих данных ChatGPT. Если ваш контент не попадёт в следующий датасет, он попадёт в следующий за ним. А конкуренты тем временем уже будут в ответах AI.
Начните с технического аудита и RSS — это занимает день-два и не требует бюджета. Остальное — наращивать постепенно.