Как пройти Senior-интервью в BigTech: фронтенд и System Design
Мы изучили около трёх часов материалов по теме технических собеседований — мок-интервью на Senior Frontend Developer, разговор с инженером Meta о реальной жизни в BigTech и полноценное System Design-интервью для Go-разработчика. Аудитория у всех трёх — опытные разработчики, которые уже знают, как писать код, но не знают, как проходить интервью. Это разные вещи.
Главный вывод, который прослеживается через все материалы: на Senior-уровне вас не проверяют на знание синтаксиса. Проверяют структуру мышления, умение аргументировать решения и способность объяснить архитектуру голосом — без подсказок и без гугла. Именно это режет кандидатов, которые технически сильны, но не готовились к формату.
Ниже — всё главное, что мы вытащили из этих материалов. Без воды, по делу.
Что реально спрашивают на Senior Frontend-интервью в 2025–2026
Разберём по блокам. Мок-интервью на Senior Frontend Developer даёт хорошее представление о структуре реального собеседования в крупной компании — и о том, какие темы считаются обязательными.
Браузерный рендеринг — это не «теория для джунов»
Первый блок вопросов — Critical Rendering Path. Кандидат должен объяснить полный процесс: от получения HTML-документа до отрисовки пикселей на экране. Это не вопрос «знаешь ли ты термин» — это вопрос на понимание, что именно блокирует рендеринг и как это влияет на производительность.
Следом идут вопросы на разницу между смежными концепциями. Типичные пары:
repaintvsreflow— и когда каждый из них триггеритсяasyncvsdefer— порядок выполнения скриптов и блокировка парсераDOMContentLoadedvsload— что успело загрузиться к каждому из событий
Senior должен не просто назвать разницу, а объяснить, какой из вариантов и когда использовать в продакшене.
Обработка ошибок: архитектура, не синтаксис
Вопрос про try...catch на Senior-интервью — это не про синтаксис. Интервьюер хочет услышать про глобальную обработку ошибок при API-запросах: как выстроить централизованную логику, чтобы не дублировать обработку в каждом компоненте.
В контексте React это означает понимание Error Boundaries — когда они спасают, а когда нет (спойлер: асинхронные ошибки они не ловят). Архитектурный ответ здесь ценится значительно выше, чем правильный синтаксис.
Code Splitting и WebSockets — обязательные темы
Code Splitting входит в блок оптимизации производительности. На Senior-уровне ожидается понимание не только того, что это такое, но и как это реализуется через динамические импорты, как это влияет на bundle size и как это соотносится с маршрутизацией.
WebSockets — отдельная тема. Интервьюер ждёт архитектурного ответа: когда использовать WebSockets, когда достаточно polling, когда лучше подойдут Server-Sent Events. Просто сказать «WebSockets — это двустороннее соединение» недостаточно.
Практическая часть: живой код под наблюдением
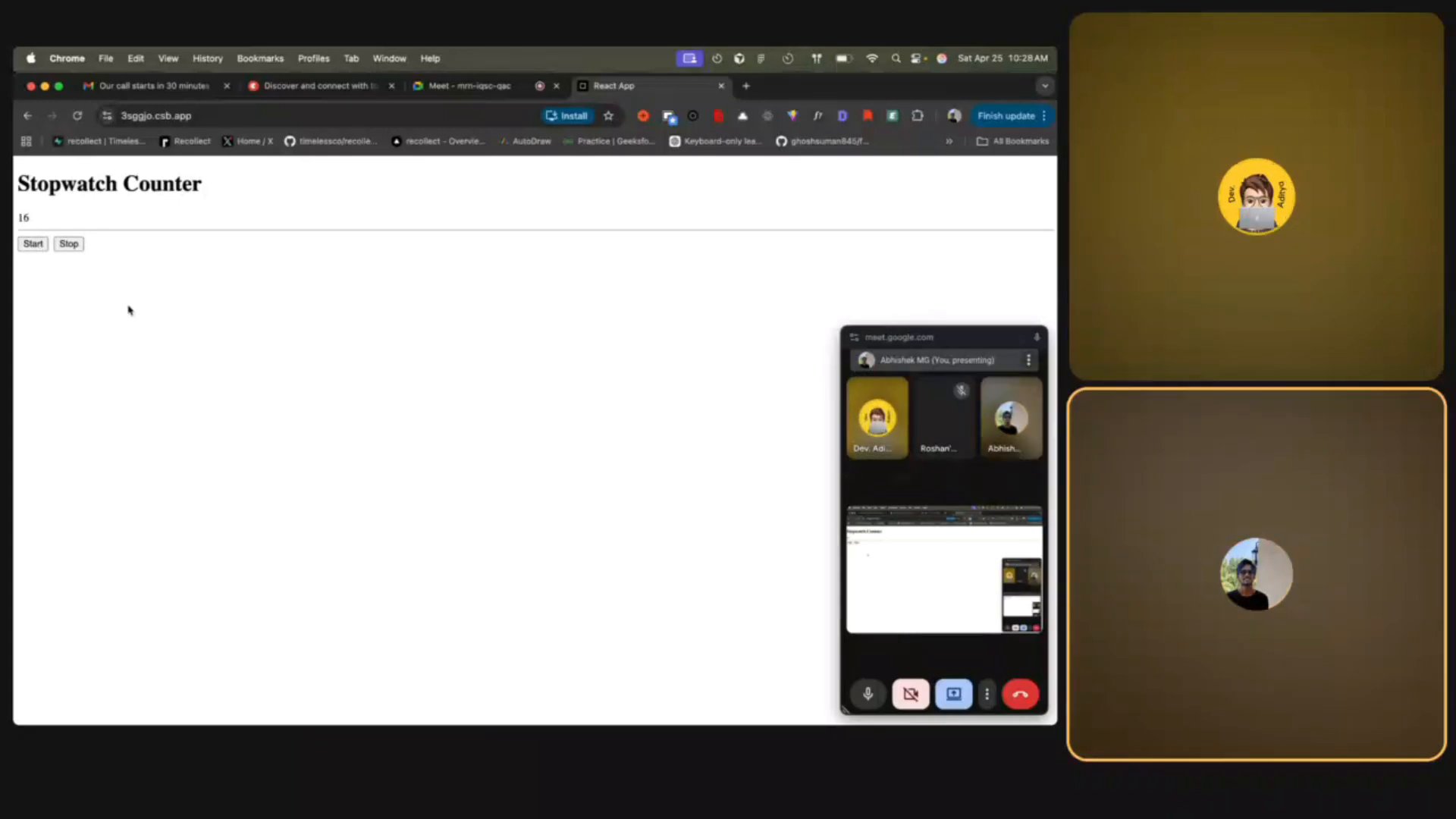
В конце интервью — реализация компонента. В рассмотренном мок-интервью это Stopwatch Counter на React: таймер с кнопками Start и Stop, запущенный прямо в браузере во время звонка.
Это важный сигнал. Крупные компании проверяют не только то, что ты знаешь теорию, но и то, можешь ли ты написать рабочий код в условиях стресса, объясняя свои решения голосом. Большую часть интервью код вообще не виден на экране — всё происходит устно. Это и есть формат, к которому нужно готовиться.
Жизнь в BigTech: что совпало с ожиданиями, а что нет
Один из материалов — разговор с Senior-инженером Meta, который работает в компании около пяти лет. Это редкий формат: человек говорит прямо, без корпоративного глянца.
Качество кода в продуктовых командах
Самое неожиданное наблюдение: качество кода в продуктовых командах BigTech может разочаровать. Причина — отсутствие узкой специализации. Один разработчик пишет и фронтенд, и бэкенд, и «хак-код» под конкретную фичу. Инфраструктурные команды (типа React-core) — другая история, там всё строго. Но продуктовая разработка часто выглядит иначе, чем представляют снаружи.
Задачи при этом оказываются не сложнее, чем в обычных компаниях. Скорее проще — потому что инфраструктура решает большую часть проблем за тебя.
Что реально хорошо
- Скорость разработки. Несмотря на масштаб, фичи выходят быстро.
- Инфраструктура. Код не компилируется локально — всё в удалённой среде, всё работает без ручной настройки окружения.
- Гибкость. Нет фиксированного времени начала работы. Требование — офис три раза в неделю, но с исключениями. Реально работать из другой страны месяц-полтора.
ИИ уже внутри рабочего процесса
В Meta разработчики используют ИИ каждый день. Конкретные сценарии:
- Редактирование технических спецификаций — документы от 50 страниц в Markdown.
- Поиск примеров использования внутренних систем в огромной кодовой базе.
- Генерация тестов — не идеально, но при правильных промптах экономит время.
- Генерация UI-компонентов по макетам из Figma.
Вывод из этого простой и неприятный: один разработчик теперь делает больше — значит, компаниям нужно меньше людей. Это одна из реальных причин сокращений в BigTech последних лет.
Как реально попасть в BigTech: без мифов
Разберём по пунктам то, что прослеживается в материалах как устойчивые наблюдения.
Реферал — это не опция, это фильтр
Резюме без реферала с большой вероятностью не дойдёт до технического скрининга. Рекрутеры получают тысячи откликов — реферал работает как сигнал доверия. Писать незнакомым людям в LinkedIn с коротким описанием своих навыков и просьбой о реферале — рабочая стратегия. Люди откликаются.
Пет-проекты в резюме — осторожно
Это контринтуитивно, но факт: большое количество сайд-проектов в резюме при отклике в BigTech воспринимается негативно. Рекрутеры читают это как сигнал о распылении внимания. Для стартапов — другая история. Для BigTech — лучше показать глубину, а не ширину.
Диплом не обязателен, опыт обязателен
Техническое высшее образование не является требованием, если есть реальный опыт в индустрии. На визу H-1B в США достаточно пяти лет технического опыта вместо профильного диплома.
Фронтенд-разработчик сегодня — это почти фулстек
Это не пожелание, а требование рынка. Senior Frontend в BigTech должен понимать:
- Основы бэкенда и баз данных
- Docker и пайплайны CI/CD — хотя бы на уровне теории
- Протоколы: WebSocket, Server-Sent Events, HTTP/2
- Балансировщики нагрузки
- Нормализацию стейта независимо от конкретной библиотеки
Не нужно быть экспертом во всём этом. Но нужно понимать, что происходит по ту сторону API.
Пять этапов BigTech-интервью: что происходит на каждом
Этап 1 — Скрининг (10–15 минут)
Проверка на адекватность. Технических задач нет. Нужно уметь рассказать о себе и объяснить интерес к компании. Звучит просто — и именно поэтому многие не готовятся.
Этап 2 — Технический скрининг (кодинг)
Минимальный порог подготовки — 300+ задач на LeetCode, распределённых по разным темам. Проверить готовность можно через контесты: если стабильно укладываешься в лимит времени — можно идти на собеседование.
Идеальный сценарий на кодинг-раунде: 1. Предложить три варианта решения с оценкой сложности (O(n²), O(n log n), O(n)) 2. Выбрать оптимальный и аргументировать выбор 3. Написать тест-план до написания кода 4. Дать оценку временной и пространственной сложности
Полезная практика — записывать себя на видео во время решения задач и разбирать запись. Неловко, но работает.
Этап 3 — Frontend System Design (~40 минут)
Оценивает сеньорность, широту знаний и умение структурировать мышление. Типичные темы:
- Оптимизация рендеринга: виртуализация списков, в том числе для сложных структур типа masonry-грида
- Выбор протокола взаимодействия с бэкендом: WebSocket vs SSE vs HTTP — с аргументацией pros/cons
- Офлайн-загрузка и кэширование
- Нормализация стейта
Лучший способ подготовки — самостоятельно «проектировать» известные приложения (Twitter, Twitch, Notion) и записывать архитектурные решения так, как если бы делал их в продакшене.
Этап 4 — Behavioral Interview
Самый частый этап провала у тех, кто прошёл все технические раунды. Люди не готовят истории заранее. Приходят и пытаются вспомнить что-то подходящее прямо во время вопроса — и это слышно.
Готовить нужно конкретные истории по методу STAR (Situation, Task, Action, Result) заранее. Минимум 8–10 историй на разные темы: конфликт с коллегой, провальный проект, сложное техническое решение, момент лидерства.
Этап 5 — Матчинг с командой
Технических вопросов нет. Резюме рассылается по командам, менеджеры проводят короткие беседы об интересах и о том, чем занимается команда. Задача кандидата — не облажаться и понять, куда реально хочется попасть.
System Design-интервью: как выглядит сильный ответ
Третий материал — мок-интервью по System Design, где кандидат проектирует сервис доставки еды (аналог Яндекс.Еды). Это один из лучших форматов для понимания того, что именно проверяют на таких интервью.
Структура сильного ответа
Шаг 1 — Функциональные требования. Формулируй чётко и лаконично. Выдели ядро продукта, не пытайся охватить всё сразу. Это показывает понимание бизнес-приоритетов.
Пример для сервиса доставки еды: - Пользователь видит список ресторанов с фильтрацией - Выбирает блюда и добавляет в корзину (корзина — один ресторан) - Оформляет и оплачивает заказ - Видит расчётное время доставки - Ресторан получает уведомление о заказе
Шаг 2 — Нефункциональные требования. Называй явно: масштабируемость, отказоустойчивость, latency. Latency раскрывай через перцентили — «99-й перцентиль не более 200 мс» звучит профессионально. «Должно работать быстро» — нет.
Шаг 3 — Расчёт нагрузки. Считай три характеристики и делай из них выводы: - RPS — 50 000 заказов в день ÷ 86 400 секунд = ~8 RPS в среднем, с пиками в завтрак/обед/ужин - Volume — объём хранимых данных (данные о заказах хранятся бессрочно) - Throughput — пропускная способность сети
Цифры без выводов — бесполезны. Интервьюер хочет услышать, что эти числа означают для архитектуры.
Шаг 4 — Архитектура. Начинай с простого. Синхронное взаимодействие между сервисами — нормальная отправная точка. Усложняй по мере роста требований. Называть Kafka, Redis и Kubernetes с первых минут — это не признак экспертизы, это сигнал тревоги для интервьюера.
Ключевые сервисы в архитектуре сервиса доставки
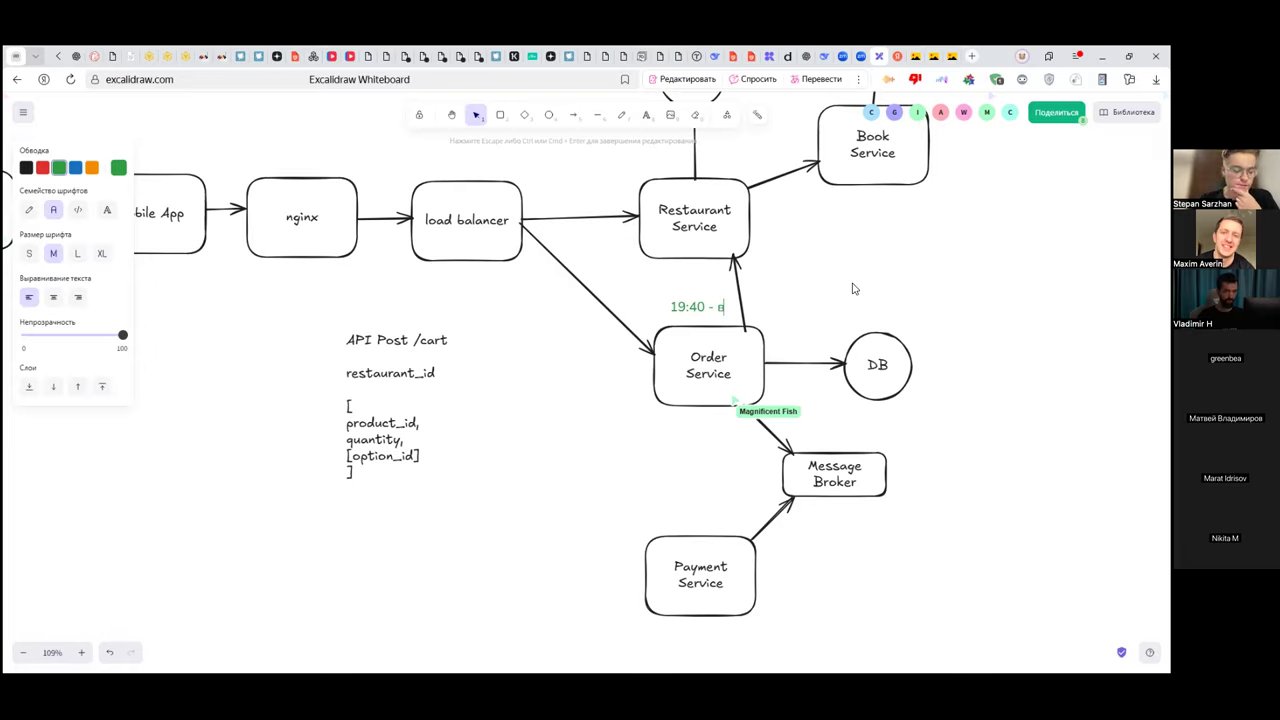
- API Gateway / Load Balancer — принимает запросы, защищает от DDoS, проверяет безопасность
- Restaurant Service — источник истины о ценах, меню, геолокации ресторанов
- Order Service — управляет корзиной и жизненным циклом заказа; на первом этапе — оркестратор
- Booking Service — бронирует остатки блюд перед оплатой; разбронирует при отмене
- Payment Service — обрабатывает оплату; обязан поддерживать идемпотентность
- Delivery Service — рассчитывает время доставки; кэширует результаты по геоквадратам в Redis
- Notification Service — отправляет push-уведомления об изменении статуса заказа
Порядок операций критически важен: сначала бронирование остатков, затем оплата. Иначе возможна ситуация, когда деньги списаны, а товара нет.
Оркестрация vs. Хореография — умей аргументировать оба
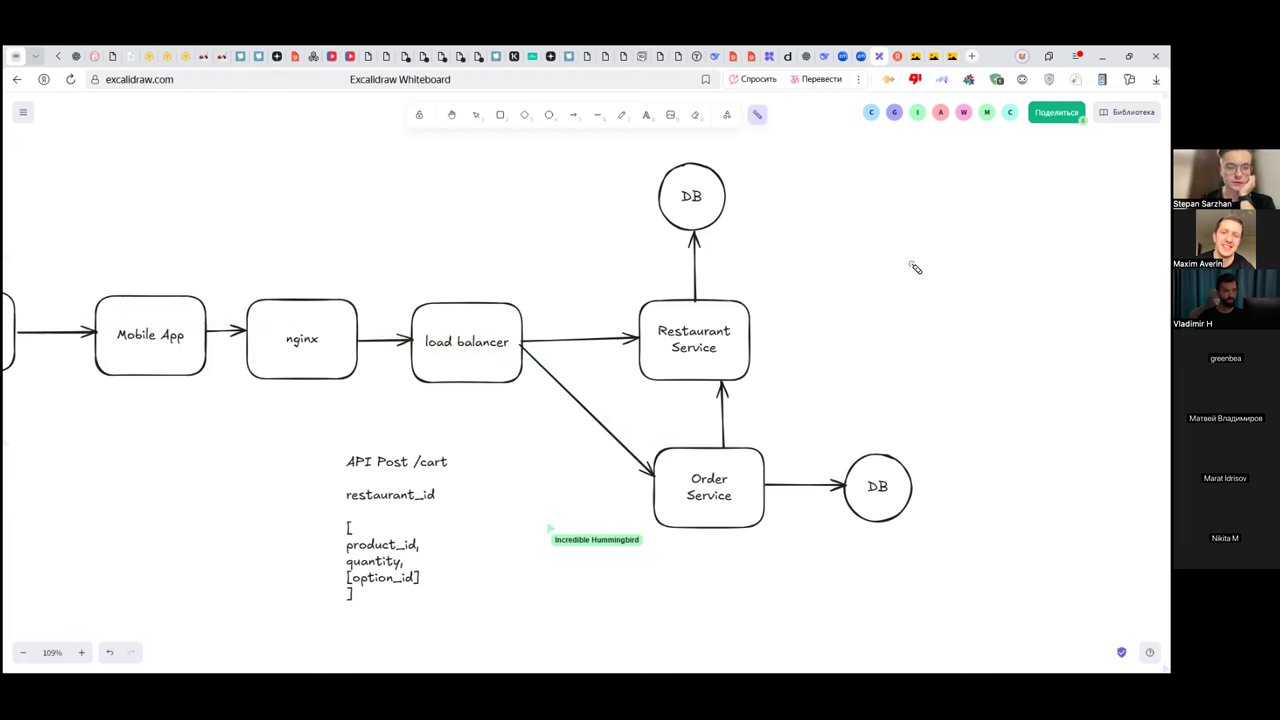
Оркестрация — Order Service как центральный координатор. Плюс: понятный flow, легко дебажить. Минус: оркестратор становится узким местом при росте нагрузки.
Хореография — каждый сервис выполняет свою функцию и передаёт управление через брокер сообщений. Плюс: каждый сервис масштабируется независимо. Минус: сложнее отслеживать общий flow, труднее дебажить распределённые цепочки.
Рабочая стратегия: начать с оркестрации для быстрого старта, перейти к хореографии при масштабировании. Это убедительнее, чем сразу предлагать максимально сложное решение.
Паттерн Outbox — обязательно знать
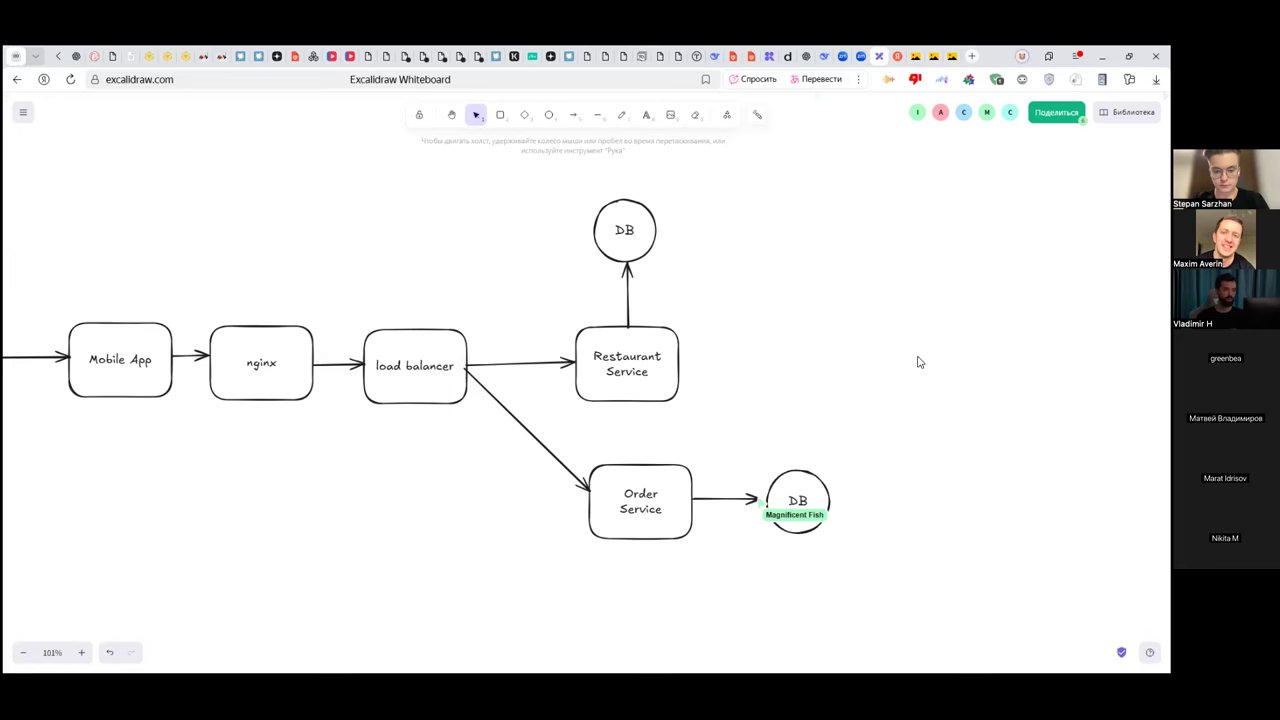
Проблема: Order Service сохранил заказ в базу данных, но упал до отправки события в Kafka. Заказ есть, событие — нет.
Решение — паттерн Outbox: сервис записывает событие в специальную таблицу в той же транзакции, что и сам заказ. Отдельный воркер читает таблицу и публикует события в Kafka. Это даёт гарантию доставки at-least-once с eventual consistency.
Идемпотентность платёжного сервиса
Payment Service вычитывает задания из брокера. При перезапуске после сбоя одно и то же сообщение может прийти дважды. Без защиты — двойное списание.
Решение: ключ идемпотентности. Варианты:
- Хэш от restaurant_id + user_id + product_id + количество
- Уникальный Order ID — проще и надёжнее, поскольку гарантированно уникален
Что нельзя забыть в финале
API. Детально описать хотя бы один ключевой эндпоинт: метод, тело запроса, коды успешного ответа (200, 201), коды ошибок (400, 404, 500). Поверхностное «POST /orders» — это не ответ.
Мониторинг. Обязательный элемент законченного решения. Минимум: метрики (CPU, сеть, throughput), алертинг, стандартный стек — Grafana + Prometheus.
Практический чек-лист: что делать прямо сейчас
Если вы готовитесь к Senior-интервью в ближайшие 3–6 месяцев:
Кодинг: - [ ] Решить 300+ задач на LeetCode по разным темам - [ ] Пройти 5–10 контестов — проверить, укладываешься ли в лимит времени - [ ] Записать себя на видео во время решения задачи и разобрать запись
Frontend-теория: - [ ] Разобрать Critical Rendering Path до деталей - [ ] Знать разницу: repaint vs reflow, async vs defer, DOMContentLoaded vs load - [ ] Понимать архитектуру глобальной обработки ошибок в React (Error Boundaries + глобальные обработчики) - [ ] Разобрать Code Splitting через динамические импорты - [ ] Знать, когда WebSocket, когда SSE, когда polling
System Design: - [ ] Самостоятельно спроектировать 5–7 известных приложений (Twitter, Twitch, Uber, Notion) - [ ] Знать паттерны: Outbox, идемпотентность, оркестрация vs хореография - [ ] Уметь считать RPS, volume, throughput и делать из них выводы - [ ] Детально расписывать хотя бы один API-эндпоинт в каждом решении - [ ] Заканчивать любой System Design блоком про мониторинг
Behavioral: - [ ] Подготовить 8–10 историй по методу STAR - [ ] Темы: конфликт, провал, сложное решение, лидерство, работа в условиях неопределённости
Организационное: - [ ] Найти рефералов через LinkedIn — писать незнакомым людям, кратко описывая свой стек - [ ] Убрать из резюме избыточное количество пет-проектов (для BigTech) - [ ] Убедиться, что резюме показывает глубину, а не ширину
Что мы заметили: где материалы сходятся, а где расходятся
Сходятся все три:
Структура мышления важнее правильного ответа. Это прослеживается и в мок-интервью на Frontend, и в System Design-собеседовании, и в рассказе о реальной жизни в BigTech. Интервьюер хочет видеть, как вы рассуждаете вслух, а не просто что вы знаете правильный термин.
Расходятся в акцентах:
Подход А (практический, из мок-интервью) делает упор на теоретическую базу и живой код — важно уметь объяснить концепцию голосом и написать рабочий компонент под наблюдением.
Подход Б (карьерный, из разговора с инженером Meta) смещает акцент на подготовку к процессу в целом: реферал, правильное резюме, behavioral-истории. Технические знания — необходимое условие, но не достаточное.
Подход В (System Design, из мок-интервью для Go-разработчика) — самый структурированный. Здесь важна последовательность: требования → расчёт нагрузки → архитектура → API → мониторинг. Пропустить любой шаг — значит дать интервьюеру повод снизить оценку.
Интересное расхождение: более консервативный взгляд рекомендует начинать с простых синхронных решений и усложнять по мере роста требований. Более агрессивный подход предполагает сразу демонстрировать знание продвинутых паттернов. По нашим наблюдениям, первый подход выигрывает — он показывает зрелость мышления, а не желание произвести впечатление терминами.
Три часа материалов сводятся к одному: Senior-интервью — это предсказуемый процесс с известными правилами. Все ресурсы для подготовки открыты. Вопросы известны заранее. Разница между теми, кто проходит, и теми, кто нет, — это не уровень интеллекта, а количество часов целенаправленной подготовки к конкретному формату.
Начните с того этапа, где вы наиболее уязвимы. Для большинства опытных разработчиков это не кодинг и не теория — это behavioral. Подготовьте истории сегодня, пока следующее интервью ещё не назначено.