
AI-агенты: как устроены, чем отличаются от чат-ботов и как запустить первого
Мы просмотрели около 110 минут свежего контента по теме AI-агентов — от базовой математики языковых моделей до рекурсивных мультиагентных систем, которые сами себя оркеструют. Материалы охватывают три уровня: «что такое LLM на самом деле», «как устроены агенты архитектурно» и «как собрать первого агента без единой строки кода». Статья полезна тем, кто уже пользуется ChatGPT или Claude, но пока не понимает, чем агент отличается от обычного чата — и почему это принципиально важно для автоматизации.
Главный вывод: агент — это не «умный чат-бот», а комбинация языковой модели и детерминированного кода, где каждый компонент делает то, что умеет лучше всего. Качество архитектуры агента важнее мощности модели внутри него. И начать можно прямо сейчас — на бесплатных инструментах, без сервера и без Python.
Что такое LLM — и почему это важно понять до всего остального
Прежде чем говорить про агентов, нужно честно разобраться с тем, что внутри. Большая языковая модель (LLM) — не думающий робот и не база знаний с поиском. Это математическая функция с миллиардами параметров, единственная задача которой — предсказать следующий токен по предыдущим.
Токен — не слово. Это часто встречающаяся последовательность символов. Словарь современных моделей содержит от 30 до 200 тысяч таких последовательностей. Когда вы отправляете запрос, текст сначала разбивается на токены, потом каждый токен превращается в вектор — набор из нескольких тысяч чисел, которые кодируют смысловую близость слов. Именно поэтому модель «знает», что «Париж», «Лондон» и «Москва» похожи, а слово «пыхтеть» — нет.
Несколько технических деталей, которые меняют понимание:
- Модель недетерминирована. Один и тот же запрос при повторном вызове даст другой ответ. Причины — ошибки округления при работе с дробями, параллелизм в видеокартах, пакетная обработка запросов. Это не баг — это архитектурное следствие.
- Параметр температуры управляет «творческостью»: значение 0 — почти всегда один и тот же предсказуемый ответ, ближе к 1 — больше вариативности.
- Контекстное окно — это «оперативная память» модели за один вызов. От 4 000 токенов у компактных моделей до 1 000 000 у некоторых современных. У русского языка токенов уходит примерно вдвое больше, чем у английского: «хороший» — 3 токена, «good» — 1. Причина — кириллица в UTF-8 занимает 2 байта на символ.
- Галлюцинирует всё. Включая самые дорогие облачные модели. Это не исправляется выбором модели — это решается архитектурой агента.
Понимание этих ограничений напрямую определяет, как правильно проектировать агента. Если вы строите систему, не зная этого — вы будете бороться с симптомами вместо причин.
Агент vs. чат-бот vs. автоматизация — три разных существа
Путаница здесь колоссальная, и свежие материалы по теме это подтверждают. Разберём по пунктам.
Чат-бот — это LLM плюс история диалога. Он предсказывает следующий токен с учётом контекста переписки. Ощущение «разговора» создаётся за счёт обучения и системного промпта, но модель не «думает» между сообщениями — она просто считает.
Детерминированный воркфлоу с LLM — это когда языковая модель встроена в фиксированную цепочку шагов. Например: пользователь пишет → модель определяет тип запроса → в зависимости от ответа выбирается одна из трёх заранее прописанных веток → результат возвращается пользователю. Это не агент. Здесь модель может лишь выбирать из заранее заданных вариантов. Добавить новую ветку без ручной переработки пайплайна нельзя.
AI-агент — система, которая может ставить промежуточные цели, планировать последовательность действий, использовать инструменты и выполнять многошаговые задачи без постоянного контроля человека. Агент не обязан ответить одним сообщением — он может последовательно вызвать браузер, API, файловую систему, базу данных, сформировать результат и задеплоить его.
Агент — это LLM плюс детерминированный код. Модель принимает решения, код их исполняет. Каждый делает то, что умеет.
Хорошая аналогия: детерминированный воркфлоу — это точный рецепт. Агент — умный стажёр, которому дали цель, а путь к ней он выбирает сам.
Из чего состоит агент — четыре компонента
Любой агент, от простейшего Telegram-бота до рекурсивной мультиагентной системы, собирается из четырёх элементов:
- Мозг (движок рассуждений) — языковая модель. GPT-4, Claude, Gemini, Qwen, Gemma — без разницы какая, важно насколько правильно она встроена в систему.
- Датчики (органы чувств) — триггеры и входящие данные. Email, Telegram-сообщение, фотография, PDF, календарь, вебхук.
- Память — краткосрочная (история текущего диалога) и долгосрочная (граф фактов, векторная база, файл memory.md).
- Инструменты (актуаторы) — то, чем агент действует. Отправка письма, вызов API, запись в Google Sheets, деплой приложения, поиск в векторной базе.

Если убрать любой из этих элементов — система деградирует. Мозг без инструментов изолирован. Инструменты без памяти не помнят, что уже сделано. Память без мозга — просто база данных.
Главное ограничение — контекст, и как с ним работают
Контекстное окно — самая практически важная проблема в агентных системах. Мы увидели в разобранных материалах несколько стратегий управления контекстом, и у каждой свои плюсы и цена.
Суммаризация
Когда диалог приближается к лимиту, специальный промпт сжимает историю. Агент продолжает работу, но теряет детали. На длинных сессиях суммаризация происходит несколько раз подряд — и начальные детали задачи «размываются». Реальный пример: агент через несколько часов работы забыл, что нужно деплоить исправленные версии на конкретный сервер — пришлось напоминать вручную.
Trimming
Жёсткое ограничение: в модель попадают только N последних сообщений. Старые теряются безвозвратно. Подходит только для коротких сессий с простыми задачами.
Субагенты
Главный агент делегирует подзадачи подчинённым — у каждого свой отдельный контекст. Детали реализации бэкенда не попадают в контекст фронтенд-агента и наоборот. Это кардинально решает проблему при правильной декомпозиции задачи.
Долгосрочная память через RAG и графы
Факты и документы хранятся в векторной базе и извлекаются по смысловому сходству запроса. Модели Mem0 и Zep идут дальше — строят граф связей между фактами. AutoMemory в Claude Code работает проще: агент сам решает, что записать в файл memory.md, который при следующем запуске автоматически попадает в системный промпт (первые 200 строк).
Правило из практики
Если хранить важные промежуточные данные не в контексте модели, а отдельно — в базе данных, файле или векторном хранилище — агент с коротким контекстным окном в 4 000 токенов может выполнять задачи, недоступные чату с окном в 200 000 токенов, если тот плохо спроектирован.
Локальные модели: зачем они нужны, если есть GPT-4
Один из разобранных материалов делает сильный практический аргумент в пользу локальных моделей, и мы его разделяем.
Облачные модели (GPT-4, Claude Opus, Gemini) удобны. Но у них есть набор проблем, которые в агентных системах становятся критическими:
- Стоимость в продакшне. Claude Opus 4.6: $5 за миллион входных токенов, $25 за миллион выходных. Агент, работающий 24/7 и тратящий $1 в час — это ~657 000 рублей в год. Десять агентов — потенциально 10 миллионов рублей ежегодно.
- Геоблокировка. Ни OpenAI, ни Anthropic не работают с российскими IP и российскими картами напрямую. Нужны промежуточные решения — например, российский агрегатор моделей с совместимым API.
- Зависимость от внешнего решения. Модель могут «притупить» перед выходом новой версии, заблокировать по региону или изменить ценовую политику.
Локальные модели лишены всех этих проблем. Они работают без интернета, бесплатно после установки, не передают данные наружу. Qwen 3.5 с контекстным окном 262 000 токенов запускается на машине с 32 ГБ оперативной памяти — такую конфигурацию можно найти на Авито в районе 25 000 рублей. Gemma 4 (4B параметров) от Google работает прямо на iPhone 15 Pro через приложение AI Edge Gallery.
Важный нюанс: хорошо спроектированный агент с небольшой локальной моделью даёт лучший результат, чем плохо спроектированный агент с самой дорогой облачной моделью. Это ключевой тезис, который мы встретили в разных формулировках в нескольких материалах — и он подтверждается реальными демонстрациями.
Реальные кейсы: что агенты делают прямо сейчас
Абстрактные объяснения мало что дают без конкретики. Собрали из изученных материалов наиболее показательные рабочие примеры.
Агент для бухгалтерских документов на локальной модели. Принимает реквизиты контрагента — из PDF, Word-файла или обычной фотографии с перспективными искажениями и бликами. Сам извлекает ИНН, КПП, БИК, расчётный счёт, заполняет шаблоны счёта и акта, проставляет дату и номер, сохраняет файлы. Работает на Qwen 3.5 локально. Когда пользователь сомневается в цене — агент даёт обоснованную рекомендацию по рынку, а при запросе «поставь дороже, сам реши» выставляет конкретную сумму.
Агент поиска отзывов по фотографии книжной обложки. На iPhone 15 Pro через AI Edge Gallery запущена Gemma 4. JavaScript-скилл обращается к книжному сервису, модель распознаёт обложку, передаёт название и автора в скилл, получает отзывы, суммаризирует их с выделением плюсов и минусов. Работает без интернет-соединения модели — только JavaScript-код уходит в сеть.

Telegram-бот для классификации спама. Классическая задача для агента: код читает новые сообщения, отправляет промпт в LLM, получает вероятность спама в формате JSON, при превышении порога (например, 95%) автоматически удаляет сообщение.
Агент для создания контента. Дважды в день сканирует тренды, находит актуальные темы, исследует их, создаёт готовые посты для LinkedIn/X/Facebook. Записывает показатели эффективности и журнал уже отправленного контента в Google Sheets — чтобы не повторяться.

Агент по генерации лидов. Собирает бизнес-данные из Google Maps, обогащает через OpenAI, заполняет недостающие поля через поиск Google, всё сохраняет в таблицу. Полностью автономно, от начала до конца.
Рекурсивная система с неограниченным горизонтом. Задача оценивается — берётся в работу целиком или рекурсивно разбивается на подзадачи. После выполнения всех подзадач запускается агрегация и оценка результата. Если задача не выполнена — добавляется новая пачка подзадач. Тест: система подготовила PDF со сравнением digital nomad виз по всем странам — агент сам разбил задачу на регионы, регионы на страны, параллельно исследовал климат, налоги, условия. По качеству результат сопоставим с тем, что даёт ChatGPT Pro за $200 в месяц.
Что делать прямо сейчас — практический чек-лист
Разбор был бы неполным без конкретных шагов. Вот два пути — в зависимости от стартовой точки.
Путь A: без кода, за один вечер
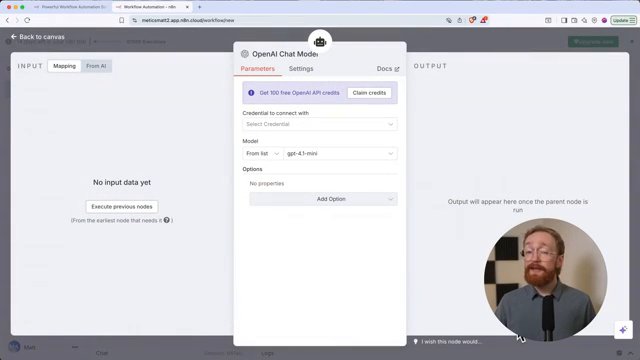
- Зарегистрируйтесь в n8n Cloud — 14 дней бесплатно, никаких серверов.
- Зайдите на platform.openai.com, пополните баланс на $5, получите API-ключ. Сохраните его сразу — OpenAI показывает его только один раз.
- Создайте новый воркфлоу в n8n: Trigger → AI Agent → Chat Model (OpenAI). Вставьте ключ.
- Добавьте два инструмента: Wikipedia (встроен) и SerpAPI (бесплатный ключ на serpapi.com). Теперь агент умеет искать в реальном времени.
- Напишите системный промпт: что делать, в каком формате, чего не делать.
- Протестируйте через встроенный чат.
- Добавьте триггер по расписанию и отправку результата на Gmail.
Это займёт от 30 минут до пары часов. Готовые шаблоны агентов (поддержка в WhatsApp, менеджер почты, генерация контента, лиды) доступны в библиотеке n8n — найдите через вкладку Templates.
Путь B: с локальной моделью
- Скачайте LM Studio и установите модель Qwen 3.5 — она бесплатна и поддерживает 262 000 токенов контекста. Компьютер с 32 ГБ RAM справится.
- Если хотите попробовать прямо на телефоне — установите Google AI Edge Gallery (iOS/Android), скачайте Gemma 4 (несколько гигабайт). Работает полностью офлайн.
- Определите одну конкретную повторяющуюся задачу: классификация сообщений, извлечение данных из документов, генерация типовых файлов.
- Спроектируйте агента с валидацией: предусмотрите, что модель может ошибиться. Встройте в код проверку формата ответа (JSON-схема) и механизм повторного запроса при ошибке.
Что мы заметили — где материалы сходятся и где расходятся
Три источника охватывают разные уровни сложности, и это заметно в подходах.
Сходятся все три в одном: агент без валидации — это не продакшн-решение, а прототип. Галлюцинации есть у всех моделей. Системная подсказка — не опция, а обязательная часть архитектуры.
Подход A (базовый уровень) фокусируется на математике LLM и локальных моделях. Здесь самый сильный аргумент в пользу локального запуска — экономика агентов 24/7 и независимость от геополитики. Особый акцент: качество агента важнее качества модели.
Подход B (продвинутый уровень) уходит в детали архитектуры — субагенты, команды агентов, MCP-протоколы, рекурсивные системы. Здесь появляются темы, которые в двух других материалах не затрагиваются вообще: наблюдаемость (observability), лимиты бюджета токенов, промпт-инъекции как реальная угроза для агентов с доступом в интернет.
Подход C (для начинающих) — самый практичный с точки зрения порога входа. Всё в n8n, без кода, с готовыми шаблонами. Архитектура из четырёх компонентов (мозг, датчики, память, инструменты) — самая доступная формулировка из всех встреченных.
Есть одно расхождение, которое мы отметили. Более базовые материалы представляют n8n почти как универсальный инструмент для любых агентов. Продвинутый подход показывает его ограничения: при получении ошибки от инструмента агент в n8n обычно прерывает выполнение задачи, тогда как терминальные агенты (Claude Code, Codex) продолжают работу, ища обходное решение. Для серьёзных продакшн-систем это существенная разница.
Ещё один нюанс, который мы считаем важным: ни один из материалов не говорит о том, что агенты заменяют разработчиков. Общий вектор — LLM усиливает того, кто умеет с ней работать. Без базового понимания программирования создать серьёзного агента не получится — можно запустить чат-бота в n8n, но не рекурсивную систему с субагентами и деплоем.
Архитектура агента важнее модели внутри него — это не красивая фраза, а практически подтверждённый факт. Хорошо спроектированный агент на локальной Qwen 3.5 закроет задачу, с которой плохо настроенный агент на Claude Opus не справится, сжигая при этом деньги 24/7.
Начните с одной задачи. Конкретной, повторяющейся, узкой. Соберите агента в n8n за вечер — и увидите, где реально нужна валидация, где ломается контекст, где системный промпт оказался недостаточно точным. Практика здесь работает быстрее любой теории. Следующая статья — про MCP-протоколы и то, как подключить к агенту внешние инструменты без написания серверного кода.